
Kubernetes Deep Dive [educative.io]
A cluster of nodes that can run applications.
-> nodes / worker machines
-> control plane / master machine / API gateway
Kubernetes is an orchestrator - deploys and manages applications. e.g. football coach manages a team and players, so kubernetes manages microservices and hardware.
Workflow:
- write app in any language/framework
- package app into its own container
- wrap each container in a pod
- deploy Pods to a cluster
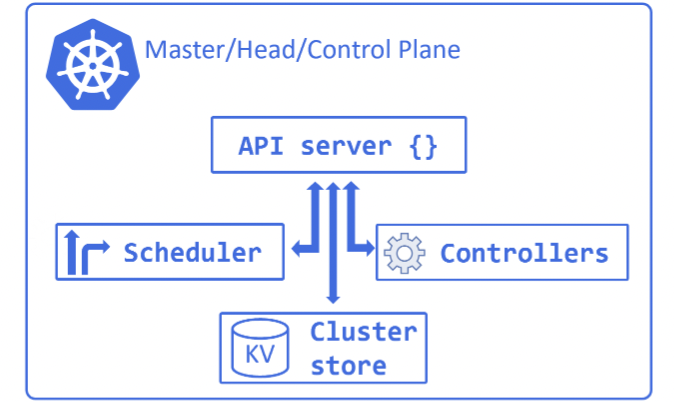
CONTROL PLANE
Contains a number of services, only for managing the cluster, is replicated for availability.
- API server: external API, accepts YAML and auth checks
- cluster store: stores configurations/YAMLs. Built on etcd (consistency more important than availiability)
- controller manager: background control loops like node controller, endpoint controller etc - background watch loops that ensure current state == desired state
- scheduler: watches API for new work tasks and assigns them to healthy nodes. Filters and ranks the nodes
NODES
Workers of a cluster. Their tasks are -
- watch API server for new work assignments
- execute work assignments
- report results to API server
They are made of 3 components -
- Kubelet: main kubernetes agent, registers with cluster and pools CPU/memory etc. Watch API server, accept and return assignments
- Container runtime: container tasks like pulling images, start-stop containers. Initially only supported Docker, now CRI (Container Runtime Interface) OSS plugin model
- Kube-proxy: for local cluster networking, handling unique IP for node and local Iptables/routing & load-balancing rules
PODS
atomic unit of scheduling - sandbox for running containers. Unit of scaling - add or remove pods, not containers.
Multiple containers per pod also possible e.g. usecase - service mesh with network proxy container.File sync service
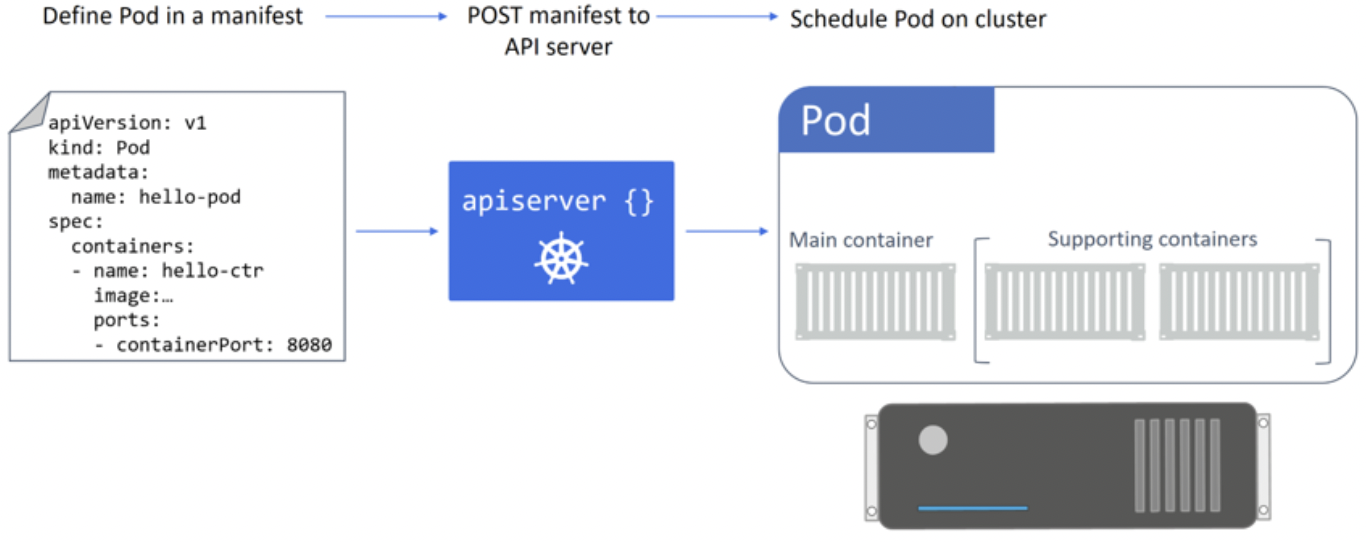
Pod is basically a special container that handles kernel namespaces like network (IP, port range, routing table), IPC namespace (unix domain sockets) etc. It shares hostname/memory address/volume.
Unix cGroups allow setting individual container resource limits.
Pod lifecycle:
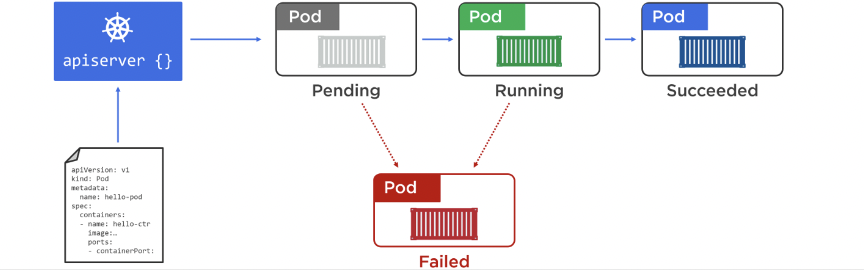
Pods are not unique and should be stateless. Use kubectl get/describe/exec/logs to check and ssh into a pod. . Once inside, add utilities like apk add curl.
DEPLOYMENTS
Pods are singletons, deployments are controllers which manage groups of pods. Deployments can handle self-healing/scaling/updates or rollbacks.
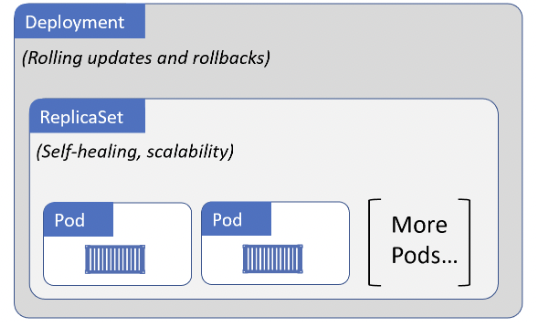
ReplicaSets implement a background reconciliation loop that checks if the current state matches the desired state or not (declarative model).
If a Deployment has been updated, the new ReplicaSet is created first, the traffic is transferred and only then the old ReplicaSet is wound down. The new and old pods are spun up/down one at a time (configurable) thus allowing seamless rolling updates with zero downtime.
If a rollback is required, the old ReplicaSet is treated as the new ReplicaSet to transition to.
Other probes like startup/readiness/liveliness also exist.
SERVICES
The external world doesn’t directly talk to a individual pod (which could disappear due to failures/scaling/updating/rollbacks etc) but to a Service which acts as a reliable network endpoint. Services allow a static IP, DNS, port, and load balancing.
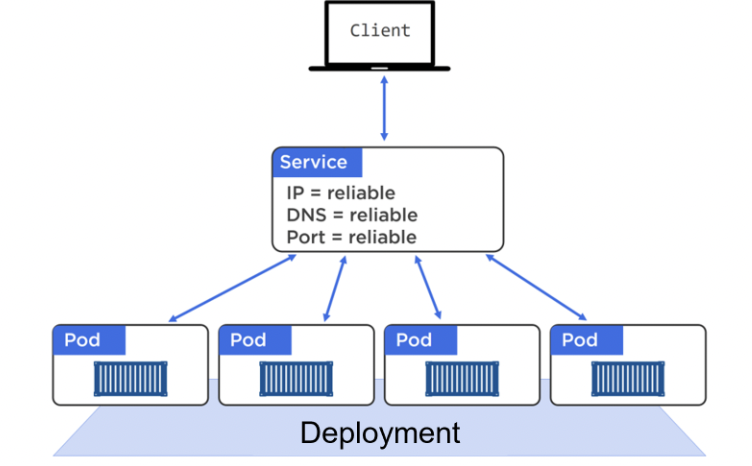
Services use labels to filter traffic to requested pods. For a Pod to receive traffic from a service, it must possess every label in the Service’s label selector.
ClusterIP is used for a stable IP address, and is accessible from everywhere in the cluster using the cluster’s internal DNS service.
A NodePort is used for receiving traffic from the external world. A NodePort is unique across the cluster and every node in the cluster knows about it, so external traffic can hit any machine which would route to the right service.
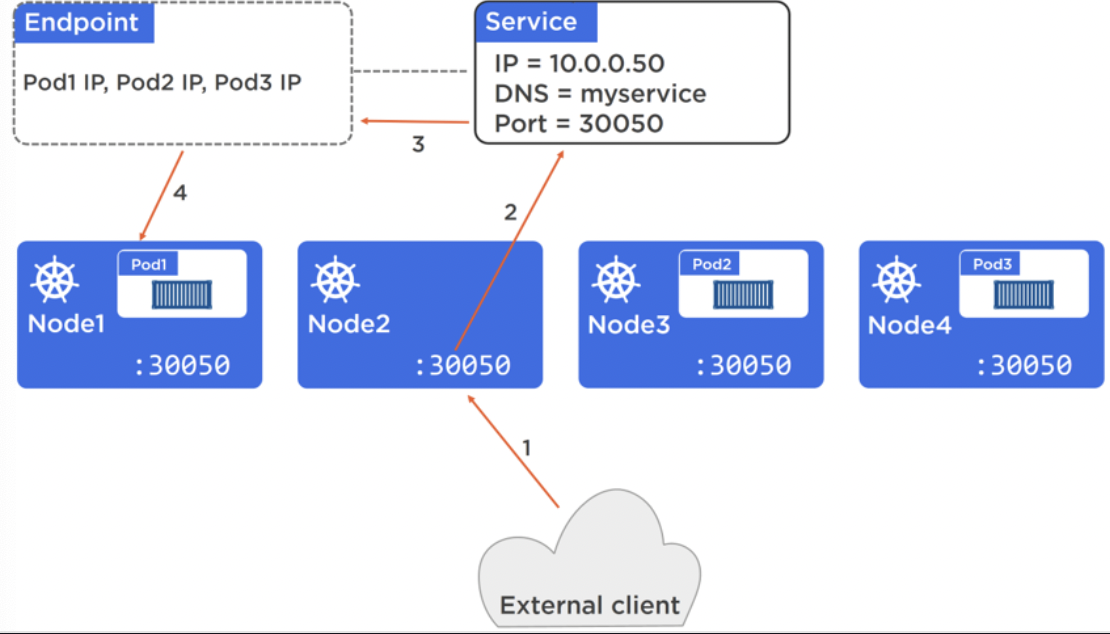
A internal DNS service is used in the cluster as it’s service registry. Services register here, not individual pods.
Service Registration summary:
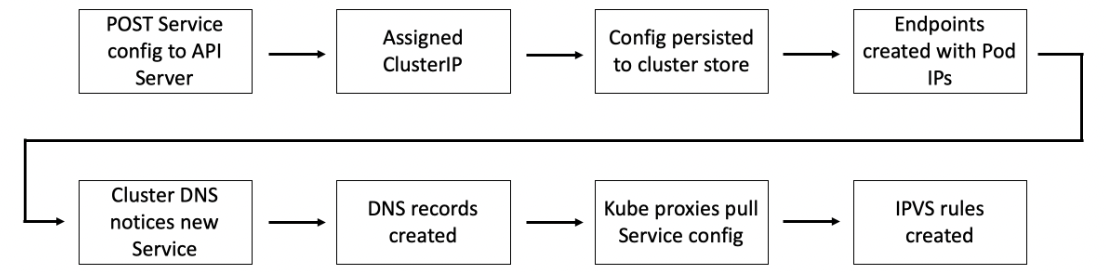
FQDN (fully qualified domain name) - e.g. <object-name>.<namespace>.svc.cluster.local.
VOLUMES
Storage providers (EMC/AWS/GCE etc external systems) connect to a plugin layer (Container Storage Interface (CSI)) - OSS plugin model. This connects to the kubernetes persisten voluume subsystem. PersistentVolumes (PV) are used to map external storage to the cluster, and PersistentVolumeClaims (PVC) are like tickets that authorize Pods to use a PV.
1 storage -> 1 PV. PV-> PVC -> Podspec mounted in container
PV can be mounted as ReadWriteOnce, ReadWriteMany (file/object storage), ReadOnlyMany (block storage).
PV reclaim policy - Delete, Retain
Difficult to manage large mappings of PVs <–> PVCs. Storage Classes -> define different classes of storage, and configure backend-specific parameters. Automatically makes a PV. Workflow - create a StorageClass (triggers creation of PV), create a PVC, create a Pod using the above.
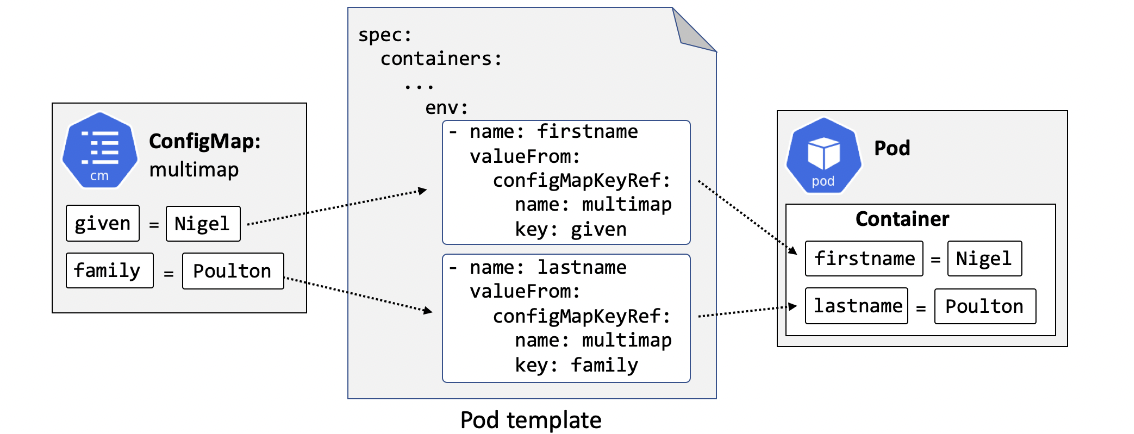
CONFIG MAPS
Used to store config data outside a Pod and dynamically inject the data at runtime. Data such as env variables, db configs, service ports etc. For sensitive data, use Secret, not ConfigMaps. Key-value pairs, injected via env vars, cmd args or volume files.
STATEFULSETS
Predictable and persistent names, DNS hostnames and volume bindings. This state/sticky ID is persisted across failures/scaling and scheduling - when pods are needed to be unique and not interchangeable. Ensure deterministic order for Pod creation and deletion.
Name given to pod is of format
Volumes associated with StatefulSet Pods survive after failures/terminations. This allows replacement pods to attach to the same storage. Failure handling is complex as potentially failed nodes may recover and try to write to the same volume as the new pod, leading to data corruption.
Headless Service is formed when clusterIP is set to None. StatefulSet pods use VolumeClaimTemplate instead of PVC.
SERVICE MESHES
Service mesh sidecar is based on envoy proxy and intercepts all traffic entering/exiting the Pod. Basically an intelligent network e.g. istio or linkerd, used to:
- automatically encrypt traffic between microservices
- provide network telemetry and observability
- advanced traffic control such as circuit breaking, fault injection, retries etc
AUTOSCALING
- Horizontal Pod Autoscaler (HPA): dynamically increases/decreases number of Pods in Deployment based on demand
- Cluster Autoscaler (CA): dynamically increases/decreases number of nodes in cluster based on demand
- Vertical Pod Autoscaler (VPA): dynamically adjust Pod size
HPA object targets a Deployment with a rule like, if any Pod in Deployment uses >60% of CPU, spin up additional Pod.
CAs periodically check kubernetes for any pending Pods waiting for node resources. If any found, it adds nodes to the cluster so these pending Pods can be scheduled.
ROLE-BASED ACCESS CONTROL (RBAC)
Allows granting of permissions based on specific users and groups.
- Subjects: users or groups managed outside of kubernetes
- Operations: what a subject is allowed to do e.g. create/list/delete
- Resources: objects on the cluster such as Pods
RBAC rule eg: admin-1 (subject) is allowed to create (operation) Pods (resource).
Role is where the resource and the allowed operation is defined, and RoleBinding connects Role with a subject.
Helm - package manager for kubernetes - abstracts complexities in Charts (equivalent of a homebrew package). Allows installing/updating/deleting kubernetes applications via Helm Charts. Share and reuse community charts.
COMMANDS CHEAT SHEET